SEAL: Self-supervised Embodied Active Learning
|
In this paper, we explore how we can build upon the data and models of Internet images and use them to adapt to robot vision without requiring any extra labels. We present a framework called Self-supervised Embodied Active Learning (SEAL). It utilizes perception models trained on internet images to learn an active exploration policy. The observations gathered by this exploration policy are labelled using 3D consistency and used to improve the perception model. We build and utilize 3D semantic maps to learn both action and perception in a completely self-supervised manner. The semantic map is used to compute an intrinsic motivation reward for training the exploration policy and for labelling the agent observations using spatio-temporal 3D consistency and label propagation. We demonstrate that the SEAL framework can be used to close the action-perception loop: it improves object detection and instance segmentation performance of a pretrained perception model by just moving around in training environments and the improved perception model can be used to improve Object Goal Navigation
SEAL: Self-Supervised Embodied Active Learning
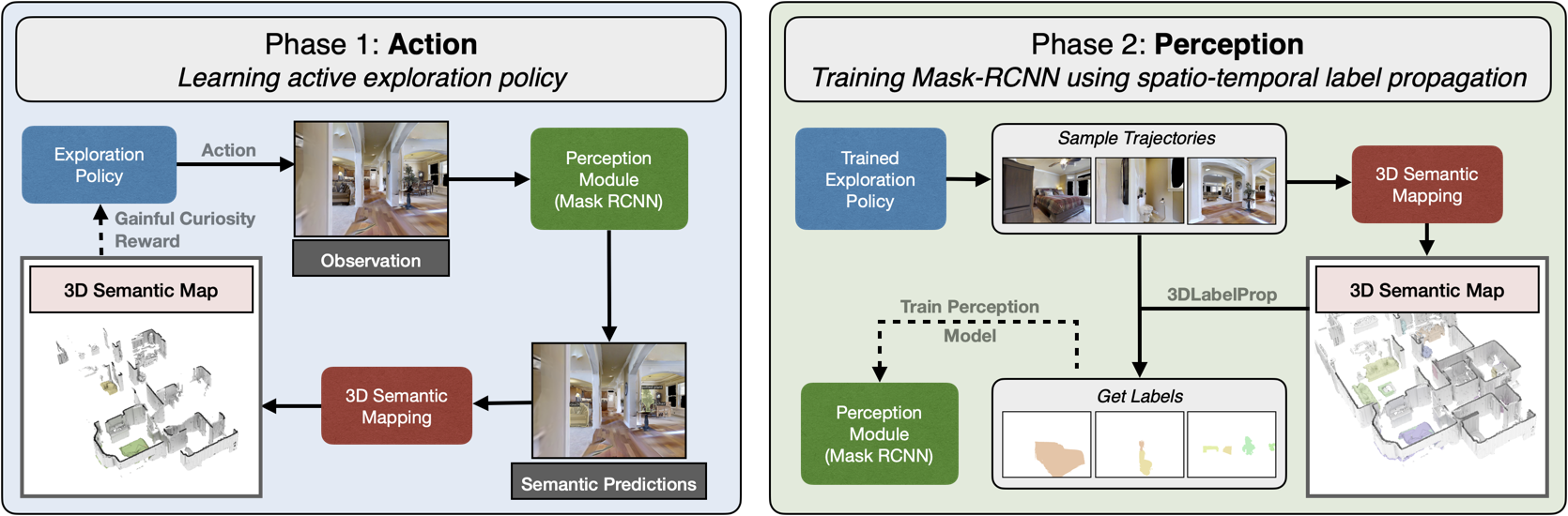
Our framework called Self-supervised Embodied Active Learning (SEAL) consists of two phases, Action, where we learn an active exploration policy, and Perception, where we train the Perception Model on data gathered using the exploration policy and labels obtained using spatio-temporal label propagation. Both action and perception are learnt in a completely self-supervised manner without requiring access to the ground-truth semantic annotations or map information.
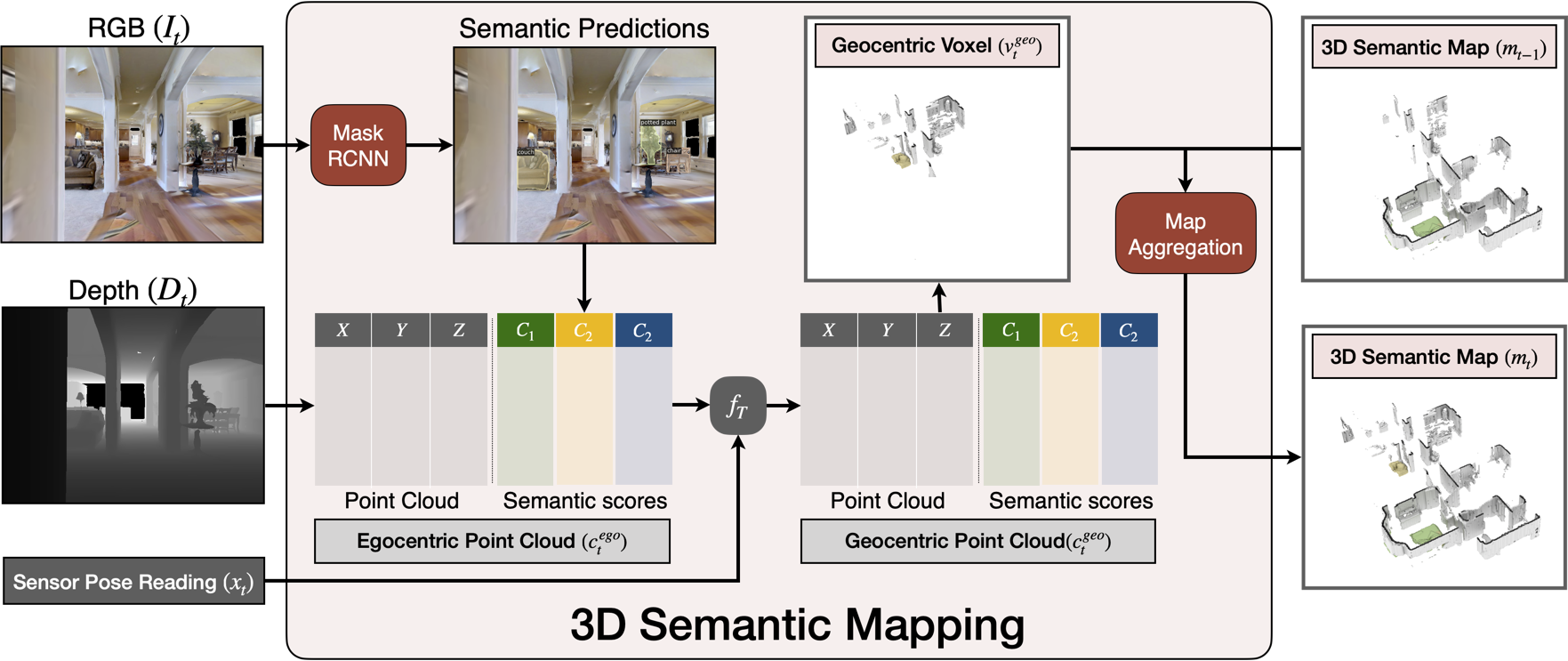
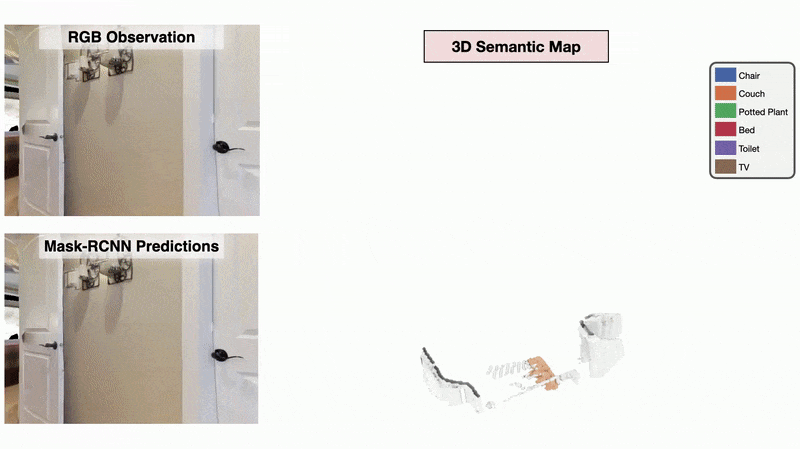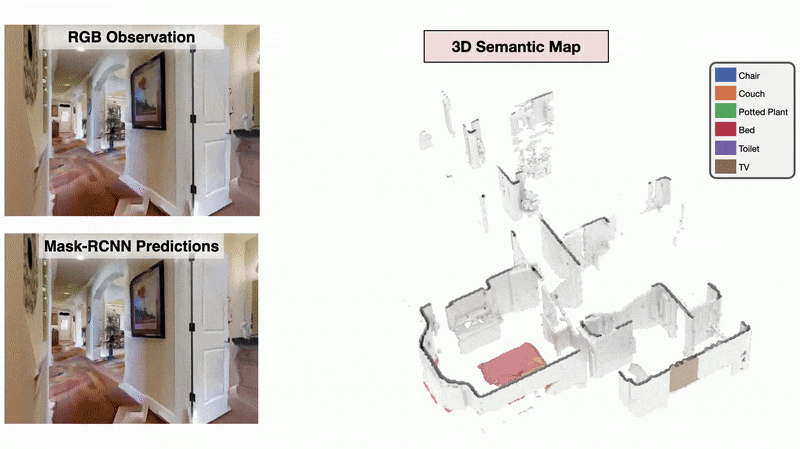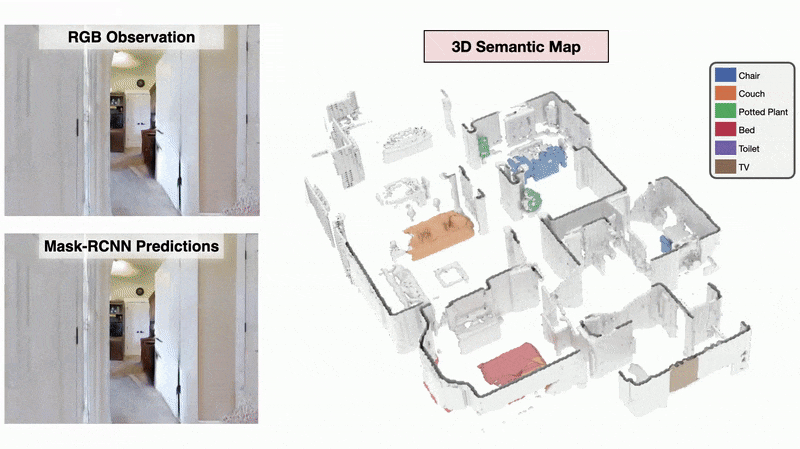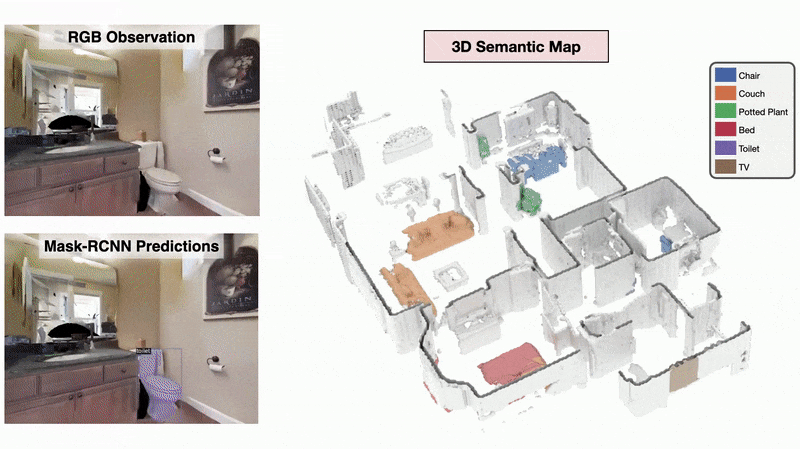
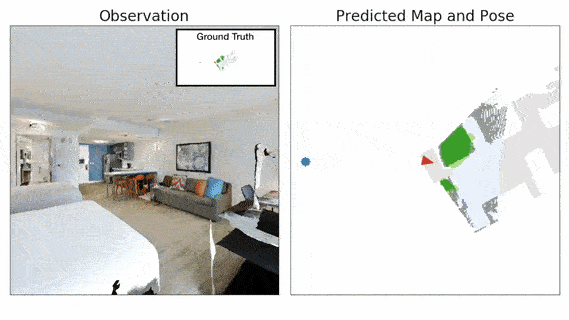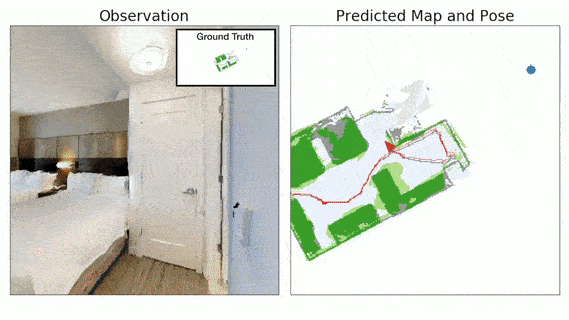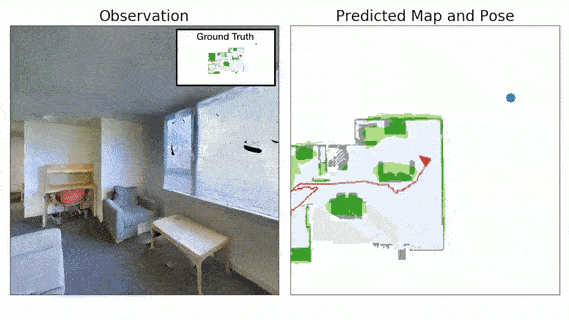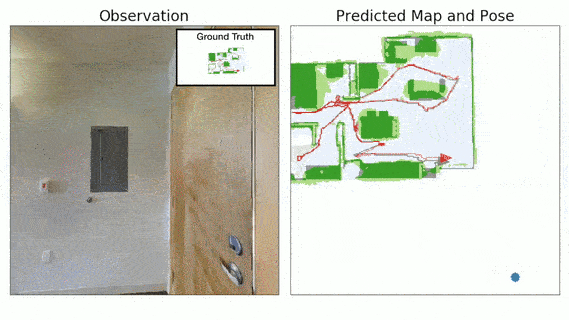
3D Semantic Mapping
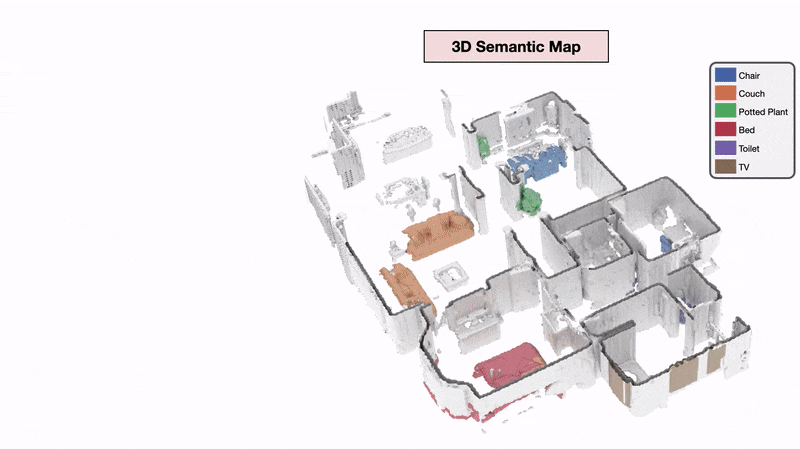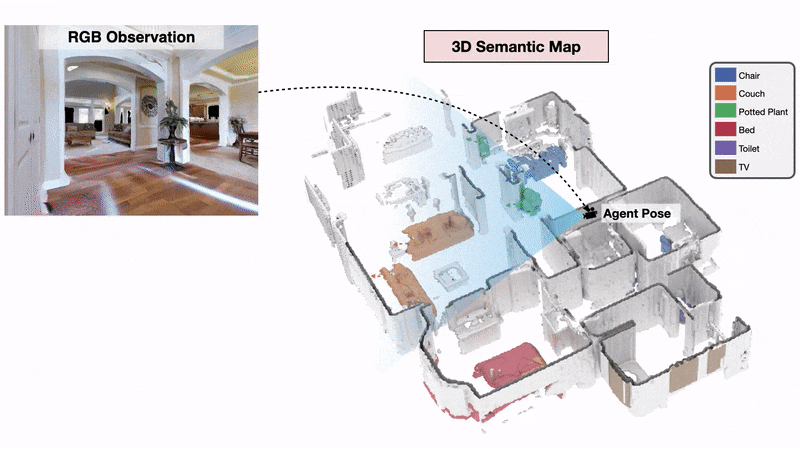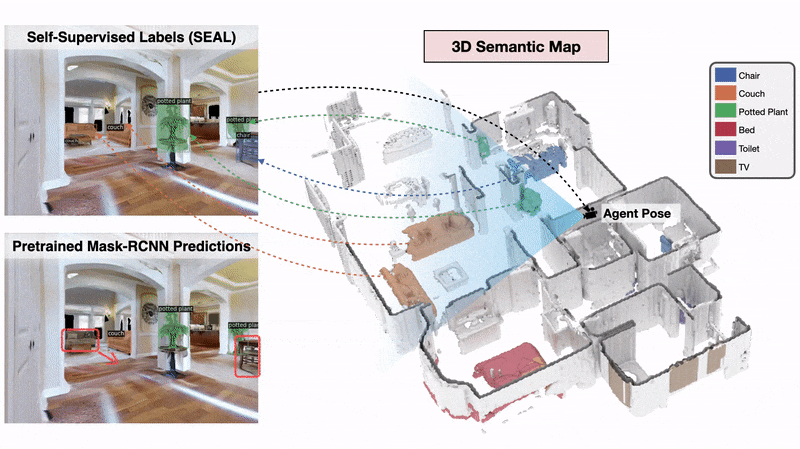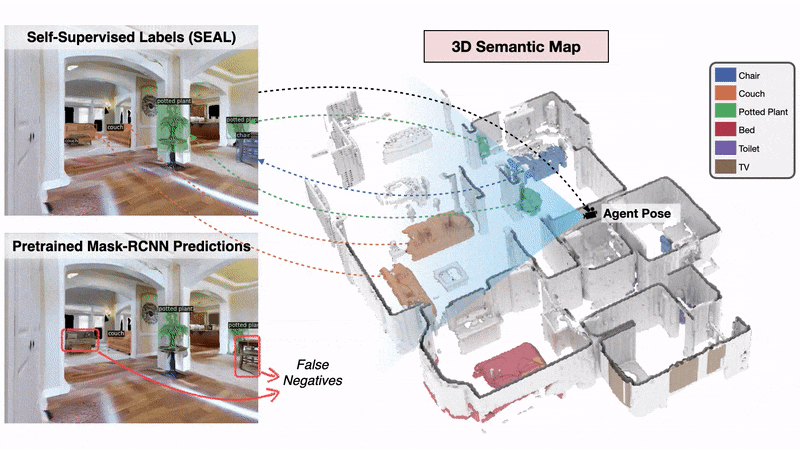
The 3D Semantic Mapping module takes in a sequence of RGB and Depth images and produces a 3D Semantic Map.
Learning Action
We define an intrinsic motivation reward called Gainful Curiosity to train the active exploration policy to learn such behavior of maximizing exploration of objects with high confidence. We define s' (= 0.9) to be the score threshold for confident predictions. The Gainful Curiosity reward is then defined to be the number of voxels in the 3D Semantic Map having greater than s' score for at least one semantic category. This reward encourages the agent to find new objects and keep looking at the object from different viewpoints until it gets a highly confident prediction for the object from at least one viewpoint.
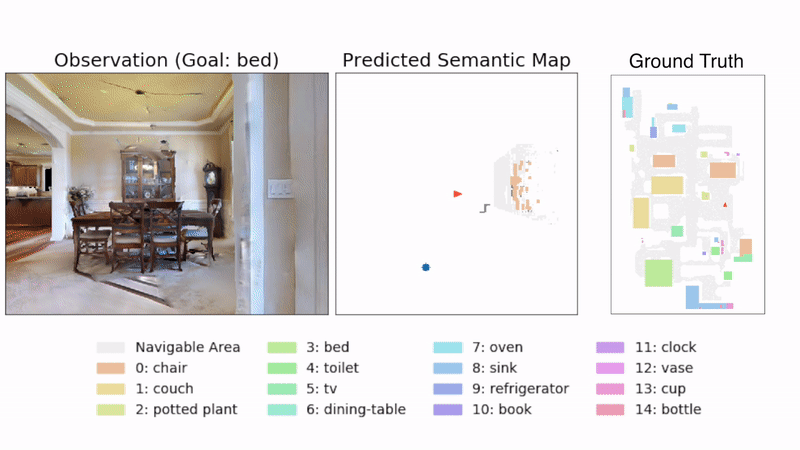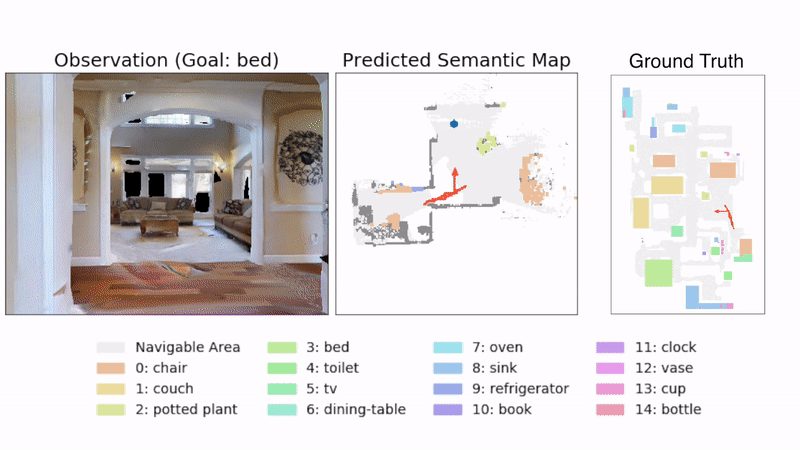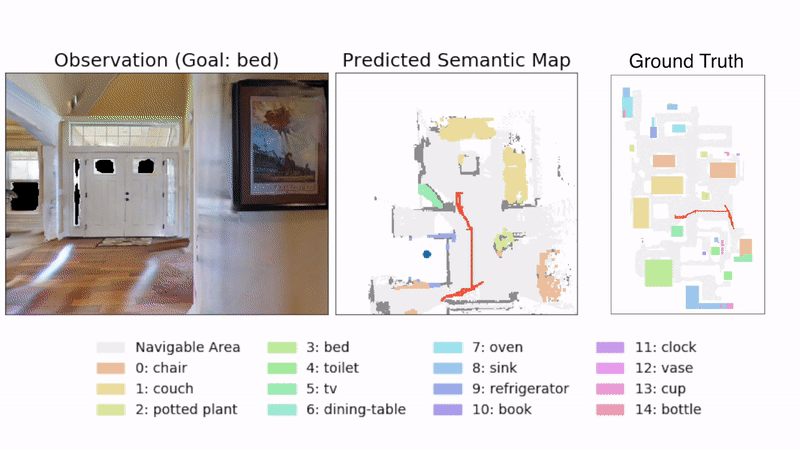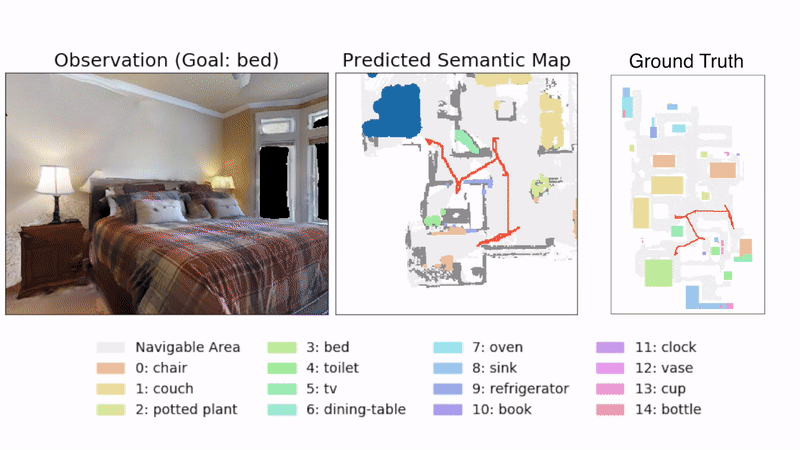
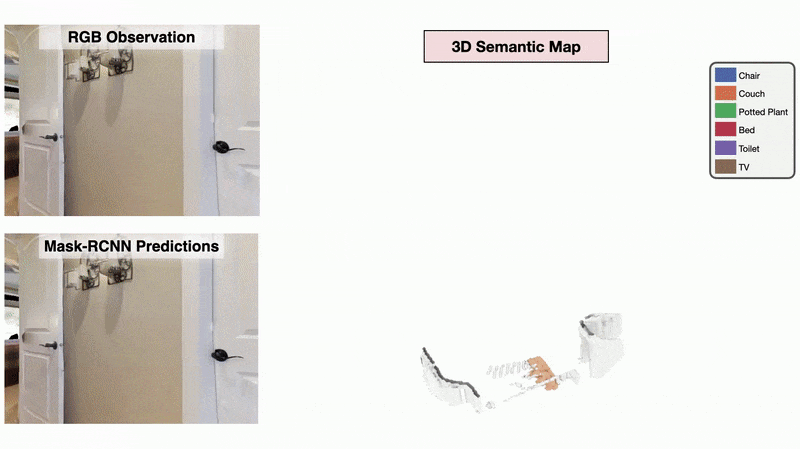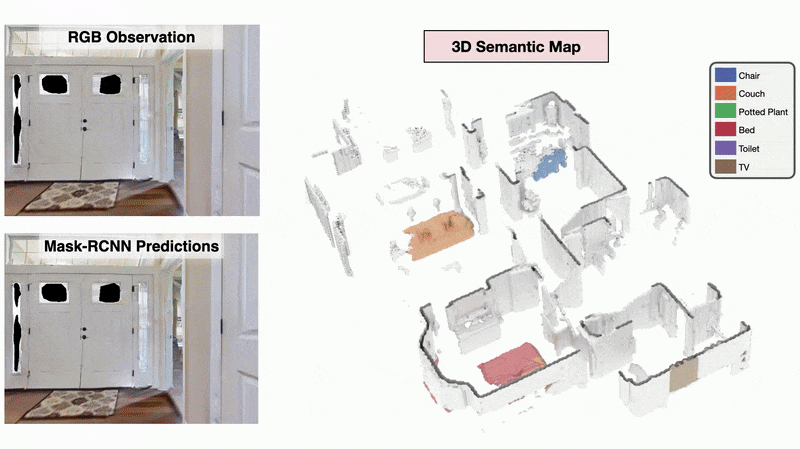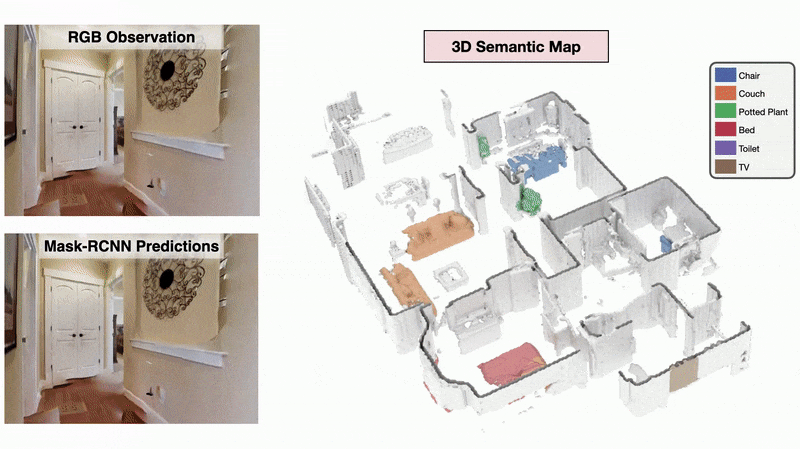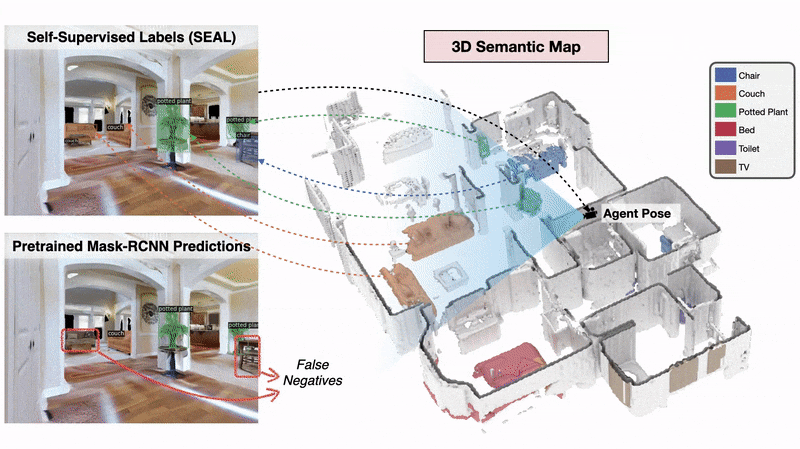
Learning Perception
We present a method called 3DLabelProp to obtain self-supervised labels from the 3D Semantic map. To perform disambiguation, each voxel is labelled with the category having the maximum score above s'. If all categories have a score less than s' for a voxel, we label it as not belonging to any object category. After labeling each voxel in the map, we find the set of connected voxels labeled with the same category to find object instances. The instance label for each pixel in each observation in the trajectory is then obtained using ray-tracing in the labeled 3D map based on the agent's pose. Pixel-wise instance labels are used to obtain masks and bounding boxes for each instance. Note that this labeling process is completely self-supervised and does not require any human annotation. The set of observations and self-supervised labels are used to fine-tune the pre-trained perception model.
Short Presentation
Paper and Bibtex
 [Paper]
[Paper]
|
|
Citation
Chaplot, D.S., Dalal, M., Gupta, S., Malik, J. and Salakhutdinov, R. 2021. SEAL: Self-supervised Embodied Active Learning. In NeurIPS.
[Bibtex]
@inproceedings{chaplot2021seal,
title={SEAL: Self-supervised Embodied Active Learning},
author={Chaplot, Devendra Singh and Dalal, Murtaza, and Gupta, Saurabh
and Malik, Jitendra and Salakhutdinov, Ruslan},
booktitle={NeurIPS},
year={2021}}
|
|
|
|
|
Related Projects
Acknowledgements
Carnegie Mellon University effort was supported in part by the US Army Grant W911NF1920104 and DSTA. UIUC effort is partially funded by NASA Grant 80NSSC21K1030. Jitendra Malik received funding support from ONR MURI (N00014-14-1-0671). Ruslan Salakhutdinov would also like to acknowledge NVIDIA’s GPU support.
Website template from here and here.
|